피드로 돌아가기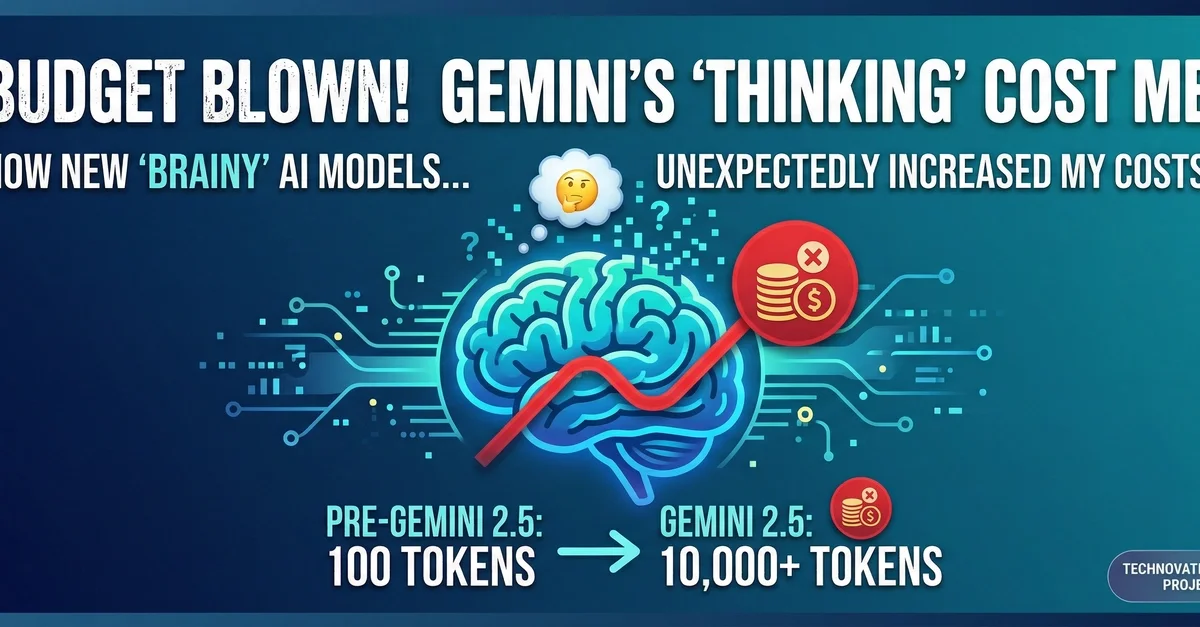
 Dev.toAI/ML
Dev.toAI/ML
원문 읽기
Thinking Budget 최적화로 Gemini 2.5 모델 비용 및 Latency 해결
Gemini Thinking: How "Brainy" Models Unexpectedly Blew My Budget
AI 요약
Context
Gemini 2.0 모델의 단종으로 인해 General Availability 단계인 Gemini 2.5 시리즈로 마이그레이션 수행. 기본 설정된 Thinking 프로세스로 인한 Token 사용량 폭증 및 응답 속도 저하라는 병목 지점 발생.
Technical Solution
- 모델별 상이한 Min Thinking Budget 제약 사항 식별을 통한 최적 모델 선정
- Gemini 2.5 Flash Lite의 높은 최소 예산(512 tokens) 대신 1 token부터 설정 가능한 Gemini 2.5 Flash 채택
- Thinking Budget을 50 tokens로 엄격히 제한하는 로직을 Fallback 시스템에 통합
- Gemini 3.x 표준인 MINIMAL, MEDIUM, HIGH 텍스트 상수를 처리하는 인터페이스 확장 설계
- 모델 변경 및 Fallback 자동화를 지원하는 추상화 레이어를 통한 유연한 모델 교체 구조 유지
실천 포인트
1. Reasoning 모델 채택 시 기본 Thinking Budget 확인
2. 모델별 최소 토큰 제약 조건(Min Thinking Budget) 비교 분석
3. 응답 품질 대비 비용 효율성을 검증하는 Latency-Cost-Quality 트레이드오프 분석 수행
4. 모델 교체 시 즉각 대응 가능한 자동화된 Fallback 매커니즘 구축