피드로 돌아가기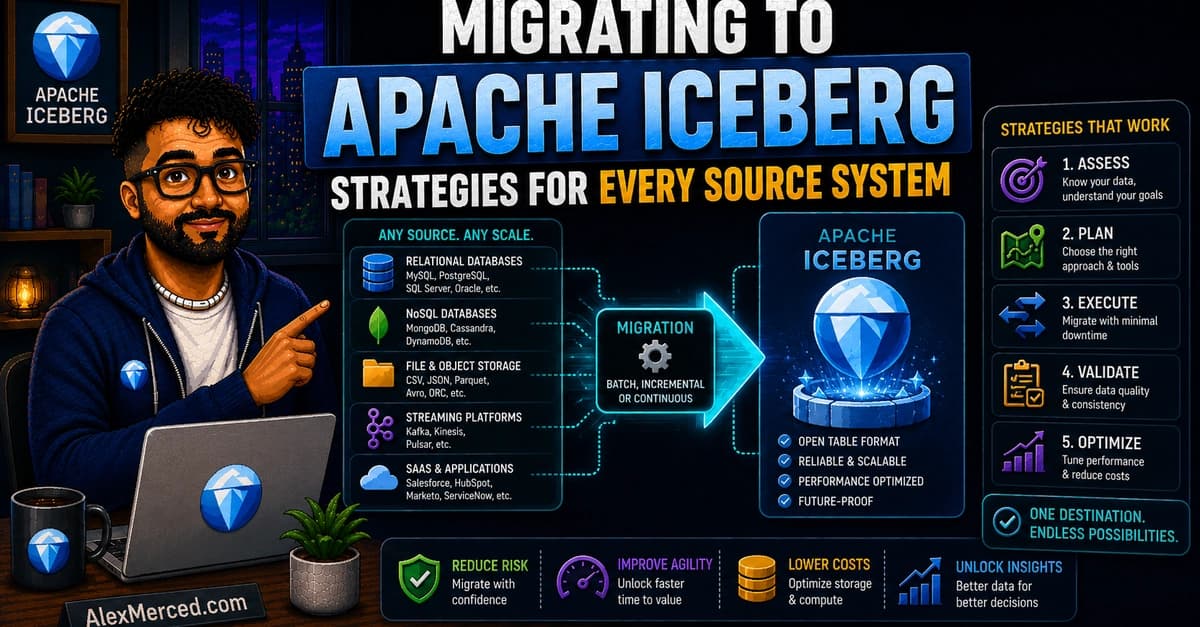
 Dev.toDatabase
Dev.toDatabase
원문 읽기
View Swap 패턴을 통한 Zero-Downtime Apache Iceberg 마이그레이션 전략
Migrating to Apache Iceberg: Strategies for Every Source System
AI 요약
Context
Hive, CSV, RDBMS 등 파편화된 레거시 데이터 소스로 인한 데이터 관리 효율성 저하 및 쿼리 성능 한계 직면. 대규모 데이터셋의 전면 교체 시 발생하는 서비스 중단 리스크와 리소스 낭비를 최소화하는 점진적 전환 구조 필요.
Technical Solution
- In-Place Migration: Parquet/ORC 파일 유지 상태에서 Metadata Tree만 생성하여 데이터 이동 없는 즉각적인 Iceberg 전환 구현
- Full Rewrite (CTAS): 소스 데이터를 전체 읽기 하여 최적의 Partitioning 및 File Size를 적용한 신규 Iceberg 테이블 재구축
- Shadow Migration: 레거시와 Iceberg 테이블을 병행 운용하며 데이터 검증 후 전환하는 Build and Swap 구조 채택
- View Swap Pattern: Dremio Semantic Layer를 활용하여 Consumer와 Physical Storage 간 추상화 계층 설계
- Incremental Migration: 전체 시스템이 아닌 고가치 테이블 단위의 순차적 전환을 통한 리스크 분산 및 점진적 가용성 확보
- Validation Pipeline: Row Count, Checksum, Boundary Value 비교를 통한 데이터 무결성 검증 후 뷰 교체 수행
실천 포인트
- 데이터 포맷이 Parquet/ORC인 경우 In-Place Migration 우선 검토 - 무중단 전환이 필수적인 프로덕션 환경에서는 View Swap 패턴 적용 - 전환 전/후의 쿼리 성능 벤치마크를 통해 Partition Strategy 적절성 검증 - Schema 차이, Timezone 처리, Null Semantics 등 데이터 정밀도 검증 단계 필수 포함 - Big Bang 방식이 아닌 테이블 단위의 점진적 마이그레이션 수행