피드로 돌아가기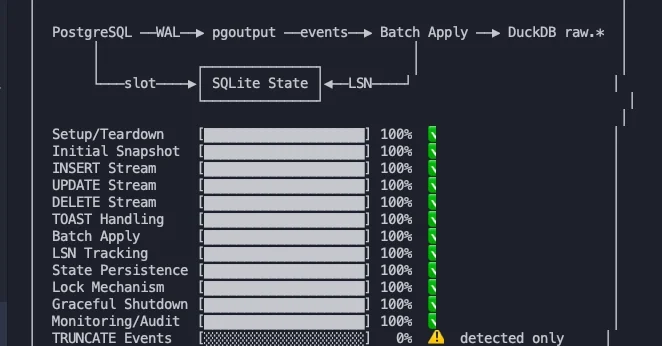
 Dev.toDatabase
Dev.toDatabase
원문 읽기
pg-warehouse가 PostgreSQL 복제를 활용해 DuckDB에 실시간 미러링하여 분산 인프라 없이 SQL 기반 AI 피처 파이프라인을 구현하는 방법을 소개합니다
pg-warehouse - A local-first data warehouse at scale without over Engineering that mirrors PostgreSQL data - no pipelines needed!
AI 요약
Context
많은 데이터 팀이 AI 피처 파이프라인을 구축할 때 Kafka, Spark, Flink, 클라우드 데이터 웨어하우스 등 무거운 분산 시스템을 사용하며 인프라 운영에 많은 시간을 소비합니다. 실제로 대부분의 파이프라인은 단순히 SQL 변환으로 feature 테이블을 생성하는 작업입니다.
Technical Solution
- PostgreSQL → WAL(Write-Ahead Log) 기반 logical replication을 통해 변경 데이터를 캡처합니다
- DuckDB local warehouse에 증분 동기화하여 columnar 형식으로 변환합니다
- SQLite 기반 state database로 restart-safe하고 crash-safe한 복제 상태를 관리합니다
- YAML 설정 파일로 테이블 매핑, primary key, watermark column을 선언적으로 정의합니다
- Hexagonal Architecture를 채택하여 core 로직과 외부 어댑터를 분리합니다
Impact
raw event stream이 200GB/day 규모라도 최종 feature 테이블은 2~10GB 수준으로 단일 노드 DuckDB 처리 용량 범위 내에 존재합니다.
Key Takeaway
90%의 AI 데이터 파이프라인은 PostgreSQL 복제와 DuckDB local analytics만으로 충분히 처리 가능하며 분산 시스템 과엔지니어링이 불필요한 복잡성을 야기합니다.
실천 포인트
PostgreSQL OLTP 환경에서 AI 피처 생성을 위한 ETL 파이프라인 구축 시 pg-warehouse를 사용하여 Kafka와 Spark 없이 CDC 기반 DuckDB 미러링으로 SQL 변환 후 Parquet 추출 방식으로 간소화된 파이프라인을 구현할 수 있습니다