피드로 돌아가기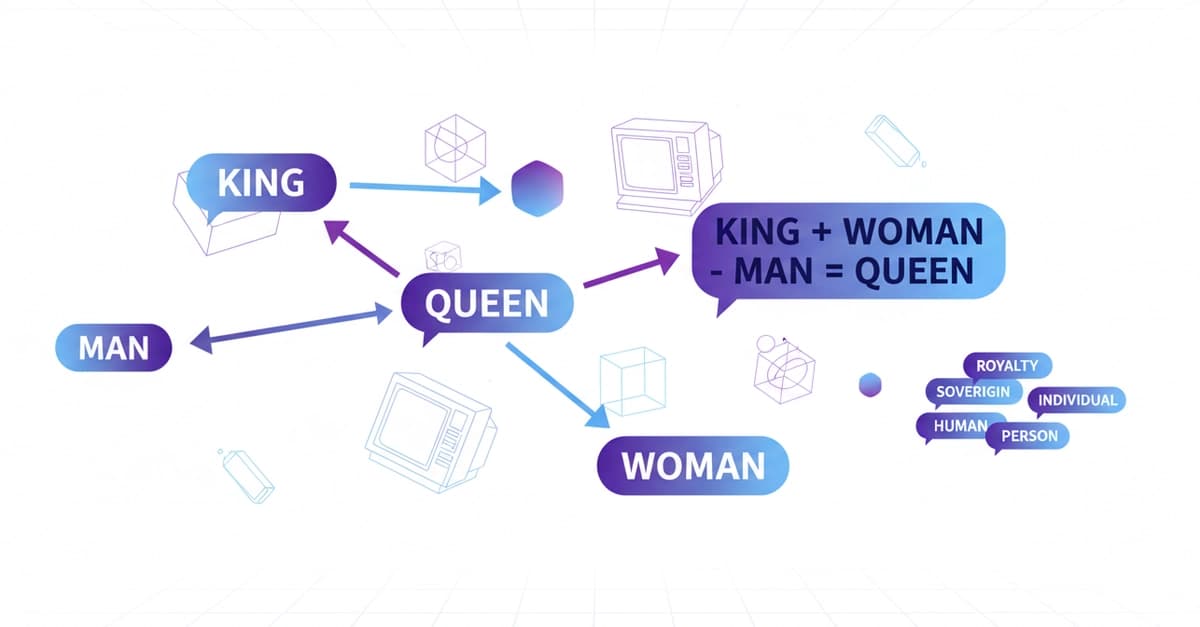
 Dev.toAI/ML
Dev.toAI/ML
원문 읽기
Keyword 매칭 한계 극복을 위한 Vector Embedding 기반 Semantic Search 설계
97. Embeddings and Vector Search: Semantic Search That Works
AI 요약
Context
기존 Keyword 기반 검색 방식은 텍스트 간의 완전 일치 여부만 판단함에 따라 의미적 유사성을 가진 문서를 검색하지 못하는 한계 존재. 단순 단어 중복률에 의존하는 구조로 인해 "Cheap hotel"과 "Affordable accommodation" 같은 동의어 처리 불가 상황 발생.
Technical Solution
- Sentence Transformers를 통한 텍스트의 고차원 밀집 벡터(Dense Vector) 변환으로 의미론적 거리 측정 구조 설계
- 벡터 크기(Magnitude)에 따른 왜곡을 방지하고 방향성 기반 유사도를 측정하기 위한 Cosine Similarity 채택
- 실시간 대규모 검색 성능 확보를 위해 FAISS의 IndexFlatIP(정밀 검색) 및 IndexIVFFlat(근사 검색) 전략 적용
- Metadata Filtering과 Persistence 기능을 통합한 ChromaDB 도입으로 단순 벡터 검색을 넘어선 실무적 Document Retrieval 체계 구축
- 모델 선택 시 Dim(384~1536)과 모델 크기(80MB~420MB) 간의 Trade-off 분석을 통한 서비스 요구사항별 최적 모델 매핑
실천 포인트
- 검색 대상 데이터의 규모와 정밀도 요구사항에 따라 FAISS Exact Search와 Approximate Search 선택 - L2 Normalization을 선행하여 Dot Product만으로 Cosine Similarity를 효율적으로 계산하는 최적화 검토 - 모델의 Dim이 클수록 품질은 향상되나 추론 속도 및 메모리 비용이 증가하므로 all-MiniLM-L6-v2부터 단계적 벤치마킹 수행 - 검색 결과의 품질 유지를 위해 특정 Similarity Threshold를 설정하여 낮은 관련성 결과 제거 로직 구현